通过LRWP加速Java技术
简介
多线程应用程序可以满足当前不断增长的业务需求,同时还可以减少所需系统的数量。但是多线程应用程序的可伸缩性却受不到了不可并发执行的代码的限制;这些串行组件对可伸缩性造成了限制,请参见 阿达姆定律 和 I/O 问题。我们的上一篇文章 Horizontal Scaling on a Vertical System Using Solaris Zones 介绍了如何使用分区(Zone)扩展 Xitami/NexSRS,即在每个分区中都运行一个副本。在每个分区中都运行一个副本可将性能提升一倍,但是这仍然不是 Xitami 可伸缩问题的解决方案。一些解决方案要么将 Long Running Web Process (LRWP) 协议迁移到 Sun Web Server,要么让 NexSRS 使用 Netscape Server API (NSAPI)。我们决定采用完全不同的方式:在 Java 中实现 LRWP 协议并在 Web 容器中运行。GlassFish 是现行可用的开放源码项目,因此我们选择使用 GlassFish 来实现我们的想法。我们期望这种方式在小型系统上的性能能够接近 Xitami/NexSRS 性能,并且可以很好地扩展到较大的系统中。
实现要快于 Xitami/NexSRS —— Xitami 是使用 C 语言编写的一款非常小的 Web 服务器,而且名列十佳 Web 服务器之一。我们的实现可以更好地扩展到较大的 CMT 系统中,但是使用 Java 实现 LRWP 在单核系统中具有 23% 的性能优势,而在 4 核系统中具有 78% 的性能优势,这显示了其从单核系统到多核系统的可伸缩性,而 Xitami 实现扩展到 4 核系统上只能达到约 15K CPM。如图 1 所示。

图 1:Xitami/C 与 GlassFish/Java 的可伸缩性比较
Long Running Web Process (LRWP)
Xitami Web 服务器使用 LRWP 协议与其对等体(peer)进行通信。对等体是与 Web 客户机通信的进程。Web 客户机可以是浏览器或其他类型的使用 HTTP 通信的客户机。 LRWP 类似于这样一种 CGI:Web 客户机请求调用 cgi-bin/context,cgi-bin/context 允许 Web 容器调用 cgi-bin 可执行程序,并将来自 Web 客户机的输入传递给可执行程序,再将输出返回给 Web 客户机。在 LRWP 中,LRWP 对等体与 LRWP 代理之间将建立一个 TCP 连接。LRWP 代理可以是 Web 容器或运行在 Web 容器中的进程,LRWP 对等体可以是运行于网络中的任何进程。连接时,LRWP 对等体将注册感兴趣的 Web 上下文。Web 上下文可以是任何上下文,比如说 /osp 、/tep 或 /cgi-bin 本身。当针对该上下文发起请求时,代理会将输入传递给 LRWP 对等体,并将对等体返回的输出发送给 Web 客户机。LRWP 代理还可以同时支持多个对等体。对等体可以是一个进程中的多个不同线程,也可以多个进程。各个对等体将建立连接并注册感的上下文。
使用 Java 实现 LRWP
要使用 Java 实现此协议,我们需要一个 Web 容器来处理 HTTP。由于 ISV 比较喜欢开放源码的 Web 容器,因此我们选择使用 GlassFish。GlassFish 是一款 Java Platform Enterprise Edition (Java EE) 应用服务器,它构建于 Apache Tomcat Web 容器之上。它使用 servlets 监听 HTTP 请求,并将请求传递给在容器中运行的 LRWP 代理。然后,LRWP 代理将请求传递给正确的 LRWP对等体,并将应答返回给 servlet。LRWP 代理服务器将注册对等体感兴趣的上下文并等待对这些上下文的请求。如果有请求匹配某个上下文,则 servlet 线程将进入上下文锁定休眠状态,然后代理会将该请求传递给 LRWP 对等体,并等待对等体的应答,然后唤醒 servlet 线程并将应答传递给它。最后,servlet 线程将应答返回给 Web 客户机。

使用 Java 实现 LRWP
我们已经实现了 LRWP 代理,即通过一个 Web 应用程序监听 "/*" 上下文,这样所有请求都将传入这个应用程序。如果请求的对象是 LRWP 对等体注册的某个上下文,则将请求传递给 LRWP 对等体进行下一步处理;如果请求的对象是未通过 LRWP 代理注册的上下文,则将该请求发送给默认 servlet 使用ServletContext RequestDispatcher 对象进行下一步处理。希望提供 LRWP 服务的 Service Provider(LRWP 对等体应用程序)必须通过 LRWP 代理使用 LRWP 协议注册自己。经过初始信息交换之后(依照 LRWP 协议),LRWP 代理和对等体之间将通过 LRWP RequestHandler 建立起连接。每个对等体应用程序将创建一个 LRWP RequestHandler 实例。对等体应用程序将注册一个相关的 URL 上下文,对该上下文的请求都将转发给对等体应用程序。LRWP 对等体可以与 LRWP 代理建立多个连接,从而通过注册相同的上下文实现负载均衡。LRWP 对等体应用程序还可以注册多个 URL 上下文。
与 LRWP 对等体和 NexSRS 的集成
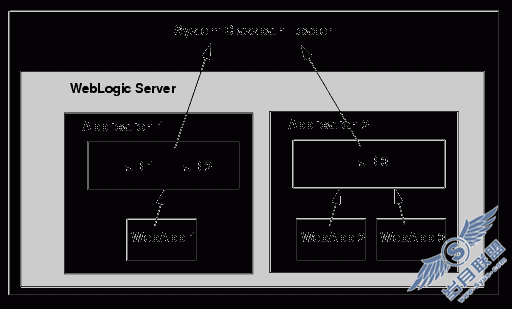
Open Settlements Protocol (OSP) 是 VoIP 载体(carrier)的一个国际标准,它为 IP 通信提供了安全机制。OSP 服务器用于授权在对等 VoIP 网关之间建立呼叫,如 图 1 所示。源网关(发起呼叫建立的网关)发送一个授权请求消息给 OSP 服务器,以获取目标网关的 IP 地址从而完成该号码的呼叫。OSP 服务器向源网关发回一个授权应答消息。授权应答消息包含可完成呼叫的目标网关的 IP 地址,以及源网关在呼叫建立过程中需要使用的数字签名令牌(digitally signed token)。源网关使用该数字签名令牌连接目标网关;然后,目标网关验证该令牌是否来自受信任源。
呼叫结束时,源网关和目标网关都会向 OSP 服务器发送一个 UsageIndication 消息。然后,OSP 服务器向源网关和目标网关发送一个 UsageConfirmation 消息表示对 UsageIndication 消息的确认,如图 2 所示。

图 2: UsageConfirmation 消息
NexSRS 是一个多线程的 OSP 服务器并且也是一个 LRWP 对等体。客户机使用 HTTP 与 NexSRS 通信。NexSRS 使用一个外部 Web 服务器处理 HTTP 请求。外部 Web 服务器使用 LRWP 协议将客户机请求发送给 NexSRS 进行处理。NexSRS 通过 HOSTNAME:1081 连接到 LRWP 代理,然后注册多个上下文(如 /osp、/tep、/cgi-bin 等)并等待来自 Web 客户机的请求。每个上下文都在单独的线程中进行处理。LRWP 代理注册上下文,并且当 Web 客户机请求类似于 http://hostname:1080/osp 这样的 URL 时,LRWP 代理会将 /osp 与 LRWP 对等体匹配并将请求传递给该对等体进行处理。
改进 LRWP 性能
优化 LRWP 代理 Java 代码
最初的设计方案是使用多线程服务器充当 ServletContainer 中的 LRWP 代理。每个 LRWP 对等体都注册在服务器中,服务器启动线程来处理连接。servlet 会将请求传递给代理,代理唤醒线程发送来自 Web 客户请求并将 servlet 线程置于休眠状态。通过唤醒 servlet 线程并将代理对等体线程置于休眠状态,可以将来自对等体的应答返回给 Web 客户机。经过修改后,采用了容器线程模型,使用 servlet 线程本身将请求传递给对等体,等待应答,然后将应答返回给 Web 客户机。此设计方案使用 LRWP 代理线程,该线程将接受来自对等体的连接并创建一个 RequestHandler 实例注册该连接。代理使用 Vector 对象作为一列 LRWP RequestHandlers 来维护处理程序。将请求转发给 LRWP 对等体以及处理来自 LRWP 对等体的应答时,此设计还添加或删除了一些处理程序。结果发现这样的设计成了一个瓶颈,因为 Vector 为同步结构,并且对方法关键部分的访问也通过 wait/notify 机制实现了同步。初次设计时,查找RequestHandlers 的方法是迭代列表并找到上下文匹配的 RequestHandler。经过修改,我们引入了一个 ContextAssistantManager 对象来管理 RequestHandlers 列表。这种方法不用再添加或删除请求处理程序,ContextAssistantManager 将跟踪使用中的处理程序并且对相同上下文的请求会将 servlet 线程置于休眠状态。
ContextAssistantManager 代码段:
class ContextAssistantManager {
public synchronized HttpProxyService getPeerService() {
ProxyServiceWrapper wrpSvc = null;
if(vectSize == 0) {
return null;
}
do {
if(lastExec < 0 || lastExec > vectSize)
lastExec = 0;
wrpSvc = (ProxyServiceWrapper)vect.get(lastExec);
lastExec++;
} while (!(wrpSvc.isFree()));
return wrpSvc;
}
}
代码示例 1:ContextAssistantManager 代码段
可改进性能的其他修改:
避免多个副本
编写代码时使用函数调用返回值作为检查条件,比如说:
if (getValue() == null) {
error;
} else {
String value = getValue();
}
开销较大,因为 getValue 生成两个 String 对象或者返回对象类型。这段代码需要改为:
String value = getValue();
if (value == null) {
error;
}
避免分配字节数组
发送给套接字的(或从套接字接收的)网络代码需要使用字节的格式。因此如果数据为 String 格式则需要将其转换为字节格式,从而分配字节数组发送或接收数据。除了使用 String 和字节数组存储数据之外,还可以使用直接映向缓冲区(如 ByteBuffer)的方式,这样可以允许创建并销毁这些对象。比如说,如果要向对等体发送一个请求,可以在 StringBuffer 中创建报头,然后将其转换为 String 以访问字节。还可以使用 ByteBuffer 来存储数据,并且可以使用 CharBuffer 来创建视图,而不是使用 StringBuffer 或 String。这同样适用于返回应答消息。
优化 GlassFish
优化 HTTPConnector Grizzly
GlassFish 的 HTTPConnector、Grizzly 默认将使用 NIO 处理客户机请求的连接。New Input/Output (NIO) 是 JDK 1.4 引入的 IO 机制,它提供了可伸缩的网络的文件 IOI,以及本地缓冲管理功能。NIO 引入了通道(channel)的概念,允许流(stream)成为通道。SocketChannel 是可选择的通道,并且允许选择读取或写入多个流。有了它,将不再需要为每个连接使用一个单独线程。因此服务器现在可以只使用少许线程处理多个客户机连接,从而提高性能并减少了线程开销。SocketChannel 可以是闭塞的也可以是非闭塞的。Grizzly 同时提供了闭塞和非闭塞实现,并且默认情况为非闭塞实现,它使用 2 个线程和最多 5 个线程处理来自客户机的请求。这种方式是可优化的,将线程数量增加到 10 个可以达到最佳性能。增加池容量也可以改进性能。池容量的增加如下所示:
<request-processing header-buffer-length-in-bytes="4096" initial-thread-count="2" request-timeout-in-seconds="30" thread-count="10" thread-increment="1"/>
<keep-alive max-connections="10000000" thread-count="1" timeout-in-seconds="30"/>
<connection-pool max-pending-count="14096" queue-size-in-bytes="14096" receive-buffer-size-in-bytes="14096" send-buffer-size-in-bytes="18192"/>
keepalive 也得到的增加,方法是将 max-connections 修改为 10000000。keepalive 似乎存在一个问题,因为增加其计数实际上并不会阻止服务器建立新连接。为解决此问题,我们将 TCP_TIME_WAIT_INTERVAL 修改为 1000,并增加了文件描述符限制。
优化垃圾收集(Garbage Collection)
<jvm-options>-Xms3400m</jvm-options>
<jvm-options>-Xmx3400m</jvm-options>
<jvm-options>-XX:UseParallelGC</jvm-options>
<jvm-options>-Xmn256m</jvm-options>
使用并行收集程序可以将 GlassFish 性能提升为 27K,如 图 1 所示。在 4 核系统上使用并行收集程序之后,原来默认收集程序出现的暂停情况消失了。将堆大小从 1400m 增加到 3400m 也可以改进性能。将其进一步增加到 7m 可以实现更大的性能提升。(GlassFish 可能与 64 位 JVM 之间存在一些问题,我们并没有尝试这一组合。)
优化 Solaris
Solaris 10 可以通过优化达到开箱即用的性能。我们将 TCP_TIME_WAIT_INTERVAL 修改为1000(删除此状态连接的时间间隔,默认为 4 分钟),增加文件描述符限制,将 TCP_CONN_REQ_MAX_Q [7] 修改为 10000 并将 TCP_CONN_REQ_MAX_Q0 修改为 1000。此外,我们还在 /etc/system 中添加了 IP:IPCL_CONN_HASH_SIZES 和 TCP_IP_ABORT_INTERVAL 并分别设置为 1000 和 500。
$ndd -set /dev/tcp tcp_time_wait_interval 1000
$ndd -set /dev/tcp tcp_conn_req_max_q 10000
$ndd -set /dev/tcp tcp_conn_req_max_q0 10000
将以下内容添加到 /etc/system
set ip:ipcl_conn_hash_sizes=10000
set tcp_ip_abort_interval=500
设置 ndd -set /dev/tcp tcp_time_wait_interval 1000 并增加文件描述符限制将性能从 4500 CPM 提升到当前数值。这与上文说到的 Keepalive 问题有关。
在基于 x86 的系统上运行
负载生成
使用 Sun Fire V280(2 个 CPU)和 ApacheBench 工具会生成负载。使用脚本启动三个 ApacheBench 实例,每个实例都向类似于 http://eagle:1080-/osp 的 URL 发送一个消息。
%./ab.sol8 -p auth.xml -n 1000000 -c 10 -k http://eagle:1080/osp &
%./ab.sol8 -p src.xml -n 1000000 -c 10 -k http://eagle:1080/osp &
%./ab.sol8 -p dest.xml -n 3000000 -c 30 -k http://eagle:1080/osp &
在服务器端,使用一个 GlassFish 实例在 1080 端口上监听对 LRWP 代理 Web 应用程序的请求,从而监听 "/*" 上下文。
测量 CPS
通过修改 nexus.log 文件测量 Calls per second (CPS) —— 日志文件将显示 calls per minute (CPM) 数据,我们需求将其转换为 CPS。ApacheBench 还可以在测试结束时输出 CPS,并且该数据将与日志文件进行比较以确保测试运行成功。
系统性能
测试环境为 x4100(双核,两个插槽,8GB,2.6Ghz)和 Solaris 10 操作系统。使用 Solaris 的动态处理器配置工具 psradm 启用/禁用核。
表 1. Xitami/NexSRS 的 CPU 使用率
核 呼叫/分(Calls per Minute) CPU 使用率 (%) nexus_server Xitami 1 8575 53 45 2 12880 44 34 4 15470 31 21
表 2. GlassFish(使用 Java 实现的 LRWP 代理)/NexSRS 的 CPU 使用率
核 呼叫/分(Calls per Minute) CPU 使用率 (%) nexus_server GlassFish 1 10569 68 28 2 20578 66 26 4 27246 43 21
性能提升
GlassFish(使用 Java 实现的 LRWP)/NexSRS 在性能上完全优于 Xitami/NexSRS(从单核到四核)。GlassFish/NexSRS 在单核系统上有 23% 的速度优势,在四核系统上有 76% 的速度优势。GlassFish/NexSRS 组合在单核系统上的 CPU 使用率为 68%,而在四核系统上的 CPU 使用率为 43%。Xitami/NexSRS 组合在单核系统上的 CPU 使用率为 53%, 而在四核系统上的 CPU 使用率为 31%。GlassFish 从单核到四核的平均 CPU 使用率 25%,而 Xitami 在单核系统上的 CPU 使用率为 45% 并且在四核系统上的 CPU 使用率为大约 21%。与 Xitami 相比,支持 NIO 的 GlassFish 使用的 CPU 时间更少,从而使 NexSRS 具有更好的可伸缩性。
结束语
从单核到四核,“使用 Java 实现的 LRWP 代理结合 GlassFish”在性能上全面超越了“使用 C 实现的 LRWP 代理结合 Xitami”1。 支持 NIO 的 GlassFish 可以很好地从单核系统扩展到四核系统,并且通过增加堆大小还可以在 64 位 JVM 上实现更大的性能提升。