Web数据挖掘技术及其在电子商务中的应用
[摘要] Internet应用的普及使得数据挖掘技术的重点已经从传统的基于数据库的应用转移到了基于Web的应用。本文以卓越亚马逊网为例,通过利用Web数据挖掘的技术帮助卓越网做出更正确的决定,使处于更有利的竞争位置。
[关键词] 数据挖掘 Web挖掘 商务 卓越亚马逊
一、引言
在Internet浪潮的冲击下,人们面临着数据爆炸的挑战;随着数据挖掘(Data Mining,DM)技术的迅速及数据库管理技术的广泛应用,人们积累的数据越来越多。如何从浩如烟 海的数据中找到内在的,如何更方便地传递、交流、获取有用的信息,挖掘这些激增数 据背后隐藏的重要信息已成为当前高科技领域研究的热点。经过长期对数据库的研究与开发 ,产生了数据挖掘技术,数据挖掘技术不仅能够对过去的数据进行查询和遍历,并且能够找出数 据间的潜在联系,从而促进信息的传递。他使数据库技术进入一个更高的阶段。
Web是一个巨大、广泛分布、高度异构、半结构化、超文本/超媒体、相互联系并且不断进化的信息仓库;也是一个巨大的文档累积的集合,包括超链接信息、访问及使用信息。传统的数据挖掘大多是针对关系数据库或数据仓库的,处理的数据具有完整的结构,但是Web包含各种类型的数据,现有的数据库管理系统无法操纵和管理大量的非结构化数据,其用户群体也表现出多样性的特点。Web数据挖掘起源于数据挖掘,目的在于可以处理非结构化的数据,Web数据的非结构化这一显著特征使Web数据挖掘更加复杂。
二、电子商务
电子商务(e-business,e-comerce)是一种利用现在先进的电子技术从事各种商业活动的方式;是一套完整的商务经营及管理信息系统;是一种利用现有的机硬件设备、软件和网络基础设施,通过一定的协议连接起来的电子网络环境进行各种各样商务活动的方式;是一种利用国际互联网进行商务活动的方式,例如:网上营销、网上客户服务、以及网上做广告、网上调查等。
电子商务可以分为企业(Business)对终端客户(Customer)的电子商务(即B2C)和企业对企业的电子商务(B2B)两种主要模式。
卓越亚马逊是一家通过互联网售卖图书的网上书店。通过卓越的Web网站,用户在购书时可以享受到很大的便利,比如要在100万种书中查找一本书,用户可以通过检索功能,只需几分钟就会找到我们想要的书。
三、Web挖掘技术与流程
数据挖掘是通过挖掘数据仓库中存储的大量数据,从中发现有意义的新的关联模式和趋势的过程。从商业的角度定义,数据挖掘是一种新的商业信息处理技术,其主要特点是对商业数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理,从中提取辅助商业决策的关键性数据。
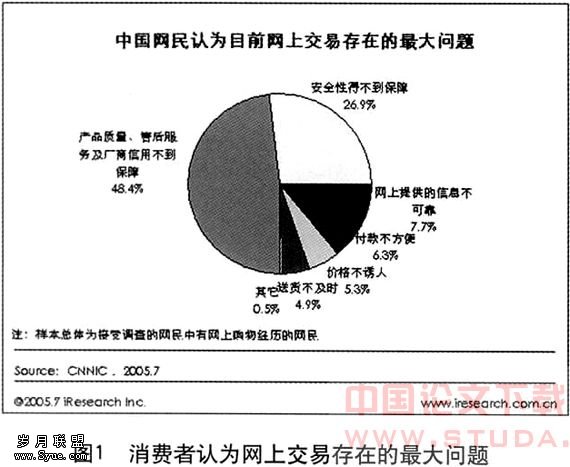
Web挖掘指使用数据挖掘技术在WWW数据中发现潜在的、有用的模式或信息。Web挖掘研究覆盖了多个研究领域,包括数据库技术、信息获取技术、统计学、人工智能中的机器学习和神经网络等。Web挖掘可以在很多方面发挥作用,如对搜索引擎的结构进行挖掘,确定权威页面,Web文档分类,Web log挖掘,智能查询,建立MetaWeb数据仓库等。一般,对Web做如下定义:Web数据挖掘是指Web从文档结构和使用的集合C中发现隐含的模式P。如果将C看作输入,P看作输出,那么Web挖掘的过程就是从输入到输出的一个映射:与传统数据和数据仓库相比,Web上的信息是非结构化或半结构化的、动态的、并且是容易造成混淆的,所以很难直接以Web网页上的数据进行数据挖掘,而必须经过必要的数据处理。典型Web数据挖掘的处理流程如图1所下:
1.查找资源:任务是从目标Web文档中得到数据,值得注意的是有时信息资源不仅限于在线Web文档,还包括电子邮件、电子文档、新闻组,或者网站的日志数据甚至是通过Web形成的交易数据库中的数据。
2.信息选择和预处理:任务是从取得的Web资源中剔除无用信息和将信息进行必要的整理。例如从Web文档中自动去除广告连接、去除多余格式标记、自动识别段落或者字段并将数据组织成规整的逻辑形式甚至是关系表。
3.模式发现:自动进行模式发现。可以在同一个站点内部或在多个站点之间进行。
4.模式分析:验证、解释上一步骤产生的模式。可以是机器自动完成,也可以是与分析人员进行交互来完成。
1.源数据的收集。在Web 挖掘中有一个很重要的步骤就是要为挖掘算法找到合适的数据。在Web使用模式数据挖掘中,数据的来源主要有以下三个方面:
(1)服务器端数据的收集(Server Level Collection)。可以从Web 服务器、代理服务器的Web log文件中收集数据,此部分信息是最简单和最方便的数据来源,它记录了每一次网页请求信息。启动Web服务器的日志记录功能后,每当浏览者通过浏览器请求一个网页时,这个请求被记录在访问日志中。代理服务器就把所记录的信息保存在文本文件中,通常以“.txt”或“.log”作为文件的扩展名。Web日志文件是由一条条记录组成,一条记录就记录了购书者对Web页面的一次访问。Web服务器的日志记录格式如表所示:
另外,Web服务器还可以存储其他的Web使用信息,比如Cookie, 以及购收者提交的查询数据。Cookie是由服务器产生的,用于记录购书者的状态或者访问路径。由于涉及到购书者的隐私问题,使用Cookie需要客户的配合。
(2)包监测技术(packet sniffing technology)。辅之于监视所有到达服务器的数据,提取其中的HTTP请求信息。此部分数据主要来自购书者的点击流(Click_stream), 用于考察购书者的行为表现。
底层信息监听过滤指监听整个网络的所有信息流量,并根据信息源主机、目标主机、服务协议端口等信息过滤掉不关心的垃圾数据,然后进行进一步的处理,如关键字的搜索等,最终将购书者感兴趣的数据发送到给定的数据接受程序,存储到数据库中进行分析统计。其工作流程如图2所示:
(3)后台数据库里的原有数据。后台数据库存储了购书者、图书和订单这三个方面信息,主要有3个数据表构成:第1个是User(用户信息数据表),他用来存放登录在卓越网的用户信息;第2个是Book(图书数据表),用来记录图书的基本信息;第3个是Orders(订单数据表),用来存放购买者在网上所下的订单情况。三个数据表的结构如图3所下:
2.数据的预处理。按照Web数据挖掘技术,将后台数据库与网络日志预处理后得到的数据相匹配建立数据挖掘库,即购书者特征数据仓库,将收集到的数据进行分门别类。依照此原理便可以将分布在不同功能模块中的信息抽取出来,然后清洗清数据。
3.数据挖掘阶段。我们把以上信息转化为多维数据模型中的星型模式来表示如下:我们将用户的一次订书看作1个事务T,采集到的多个订书记录T组成事务数据库D,它由N个二维数组组成,数组的行集为所有登录记录样本的集合,列集为特征集,事务的惟一标识符为SrcIP。Web数据挖掘技术实现的总体流程如下:? (1)确立目标样本,即由用户选择目标文本,作为提取用户的特征信息。
(2)提取特征信息,即根据目标样本的词频分布,从统计词典中提取出挖掘目标的特征向量并出相应的权值。
(3)网络信息获取,即先利用搜索引擎站点选择待采集站点,再利用Robot程序采集静态Web页面,最后获取被访问站点网络数据库中的动态信息,生成WWW资源索引库。
(4)信息特征匹配,即提取索引库中的源信息的特征向量,并与目标样本的特征向量进行匹配,将符合阈值条件的信息返回给用户。
Web数据挖掘还有待进一步的研究,尤其是近来对Web内容挖掘方面集中在信息集成,如建立基于Web的知识库或基于Web的数据仓库的研究上,但这种访求同样存在很多的问题。但建立一个基于Web数据仓库的数据挖掘系统仍是一种值得研究的方法。