树模型在慢性乙肝与肝硬化和肝癌临床诊断中的应用
作者:王剑,刘殿武,曹国玉,李伟勇,李金奎
【摘要】 目的: 利用决策树模型挖掘常见的临床检验资料信息,进一步提高慢性乙型肝炎及相关疾病的确诊率. 方法: 将临床收集的102例慢性乙肝患者和80例肝癌及肝硬化患者常见的17种信息和临床检测结果综合分析,利用决策树卡方自动交互探测(CHAID)和分类与回归树(CRT)两种算法构建预测模型,并采用正确预测率和交互印证对其进行风险评估. 结果: 进入CHAID和CRT两种算法模型的主要变量是年龄和胆红素指标及职业等,两模型预测慢性乙型和肝炎肝硬化及肝癌的总体准确率分别为71.4%和74.2%. 结论: 决策树模型在数据挖掘,资料再利用方面效果良好.
【关键词】 肝炎,乙型;决策树;诊断
0引言
在已知各型肝炎中,乙型病毒性肝炎的危害最严重[1] . 乙型病毒性肝炎极易为肝硬化、肝癌,因此如何早期诊断并加以区分具有重大的临床意义. 目前肝硬化及肝癌的诊断主要依赖于血清学和影像学检测等,而金标准肝脏穿刺的使用多受限制[2-3]. 在目前尚无特异性生物标志的情况下,充分利用现有的临床检测结果,通过高效的统计方法,挖掘数据内在的信息以提高诊断准确性,是目前较为可行的方法之一[4-5]. 本研究试图利用决策树模型在此方面做有益的探索.
1材料和方法
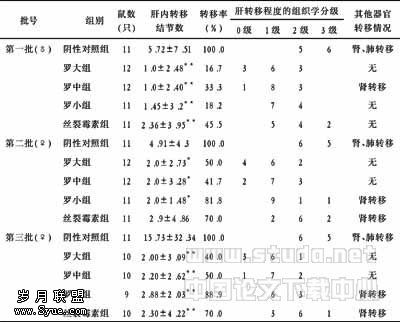
1.1材料收集2007?03/2007?05河北省石家庄市传染病的部分住院患者182例,其中慢性乙肝102例,肝癌及肝硬化者80例. 以上病例均符合国家2005?12制定的《慢性乙型肝炎防治指南》的诊断标准,并排除合并其他型别的感染[6-7],部分病例经过肝脏穿刺病理证实,肝癌患者全部经病理证实.
1.2方法
1.2.1数据来源乙型病毒性肝炎患者的病毒DNA定量采用适时荧光PCR方法,乙肝5项检测采用酶免疫法,肝功能等检测采用常规生化方法. 数据采集均符合医学伦要求.
1.2.2统计方法模型构建利用SPSS15.0统计软件,决策树研究共有4种不同算法,本次研究采用卡方自动交互探测(chi?squared automatic interaction detection, CHAID)和分类与回归树(classification and regression tree, CRT)两种算法对各变量进行预测,因为CHAID可以进行多分类结点划分,CRT只能进行二分类结点划分,具有一定代表性. 自变量的重要性依据对应变量反应程度的大小依次排列,结点划分水准定为0.05. 研究变量的赋值情况如表1.
表1各研究变量赋值明细表(略)
2结果
2.1患者资料基本情况收集的182例乙型肝炎患者中男性118例(64.8%),女性64例(35.2%),年龄12~76(45.4±8.7)岁.
2.2决策树模型汇总不同算法下乙型病毒性肝炎和肝硬化及肝癌诊断决策树主要技术指标见表2.
表2慢性乙型肝炎与肝硬化及肝癌诊断决策树(略)
2.3决策树模型依以上技术指标,用CHAID和CRT两种算法构造树模型图分别见图1,2. 其中CHAID模型的预测变量分别是年龄、胆红素水平和职业等因素,按目标效应响应率从高到低的顺序排列(即出现肝硬化和肝癌的危险性高低),分别为结点6(87.5%),结点5(54.5%),结点7(51.2%),结点4(18.4%)和结点1(13.9%),即在基本条件满足的情况下,年龄大于51岁,职业为农民或个体者,患肝硬化和肝癌的危险性最高. 而CRT模型的预测变量则是胆红素水平和年龄,按目标效应响应率从高到低的顺序排列(即出现硬化及肝癌危险性高低),分别为结点4(74.6%),结点3(36.1%),结点1(14.8%),即当胆红素水平高于14.3,同时年龄大于47.5岁者,患肝炎肝硬化及肝癌危险性最大.
图1慢性乙型肝炎和肝硬化及肝癌的诊断决策树形图(CHAID)(略)
图2慢性乙型肝炎和肝硬化及肝癌诊断决策树形图 (CRT)(略)
2.4决策树模型的分类评价和风险评估用CHAID和CRT两种算法构建的决策树模型,可将不同特征的患者预测为相对应的目标,其正确分类分别达到71.4%和74.2%(表3),说明模型的拟合效果良好. 交互印证的风险评估表明,CHAID和CRT两种模型的风险分别为0.451和0.352,标准误为0.037和0.035,虽在可接受范围内,但前者稍高,有一定风险.
表3慢性乙型肝炎与肝硬化及肝癌诊断决策树模型的分类(略)
注: 括弧内、外分别是CRT和CHAID算法.
3讨论
乙型肝炎患者极易为肝硬化及肝癌,而早期肝硬化和肝癌因临床症状不典型,常常被患者忽视,直到中晚期才被发现,临床十分被动. 本研究试图对常规临床监测数据进行挖掘,以发现隐含的、有预测价值的信息,达到早期预警[8-9].
决策树模型构建一般有4种算法,CRT和QUEST算法得到的树结构模型每个结点有2个分支,称为二叉树. CHAID和EXHAUSTIVE CHAID算法允许结点含有多于2个子结点的树称为多叉树,我们在两类算法中各取一类,即CHAID和CRT,目的在于借助这一高效的统计手段,充分利用现有资料,构建树形图为临床服务. 值得注意的是,在两种树模型中,反映肝纤维化的四项指标透明质酸(HA)、层连蛋白(LN)、Ⅲ型前胶原(PCⅢ)和Ⅳ型胶原(Ⅳ?C)均未出现,反映出该四项指标应用价值的局限性,即仅作一次检测很难准确判断肝损程度,在应用时要反复多次检测肝纤四项,动态观察,才能判断和掌握病情. 这对于临床实践有一定指导意义.
比较表2和图2,我们会发现尽管CRT算法中引入模型的变量有10个,但在决策树形图中并未完全显示,这是由于最大树深度是人为设置的,其目的就是不要使 “树”长得过于“茂盛”,否则模型的实用性将大大降低. 两个模型中被引入的变量相似,主要是年龄和胆红素等,与临床实际吻和的很好. 对已经构建好的决策树模型进行分类评价,决策树模型的正确预测率高达70%以上,拟合效果很好,而利用交互印证进行风险评估,风险均在可接受范围内. 综上,决策树模型在实际临床应用中具有良好的和使用价值.
【参考】
[1] 姜宝法. 病毒性肝炎[A]//李力明. 流行病学[M]. 5版. 北京:人民卫生出版社,2003:477.
[2] 于晓辉,赵连三,张秀辉,等. 慢性乙型肝炎病理与临床诊断的一致性[J]. 胃肠病和肝脏病杂志,2005,14(1):71-73.
[3] 刘杰,王吉耀,陆晔. 血清纤维化指标对肝纤维化诊断价值的研究[J]. 中华内科杂志,2006,45(6):475-477.
[4] 张辉,李军,钱宗才,等. 基于数据挖掘技术的骨肿瘤诊断知识的自动获取[J]. 第四军医大学学报,2004,25(7):669-670.
[5] 张晓东. 数据挖掘技术在肺癌生存期预测中的应用探讨[J]. 卫生统计,2006,13(4):324-328.
[6] 张文宏,翁心华,庄辉. 《慢性乙型肝炎防治指南》专家讨论会纪要[J]. 中华肝脏病杂志,2006,14(5):390-392.
[7] 中华医学会. 病毒性肝炎防治方案[J]. 中华传染病杂志,2001,19(1):56-62.
[8] Jonathau BL Bard. Anatomics: the intersection of anatomy and bioinformation[J]. Janat,2005,206(1):1-16.
[9] William P. The role of data mining in turning Bio?data into Bioinformation[J]. Bioinformation,2007,1(9):351-355.